First, a picture is worth a ... what was that again?
Here is an LRU latch waits graph. See if you can guess when lruskips went from 0 to 100: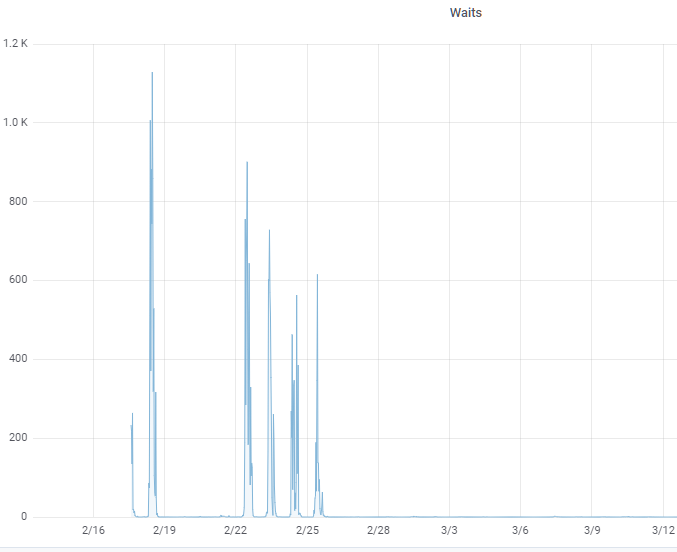
Oh yeah, a thousand words from the development team ...
"In read-heavy workloads with -lruskips 0, the LRU can be one of the most active latches, if not the most active. This can throttle read throughput. Even a pretty small value can significantly change things. Think about -lruskips 10. That means instead of moving a given block to the MRU end of the chain every time it is accessed, and locking the LRU latch to do so, you are only doing so once in every ten accesses. That doesn’t necessarily mean an overall reduction of 90%. I think that would depend on how random the block access is. But it is still a very big overall reduction in latch locking.
In databases where I have looked at the latch statistics (which have typically either been -lruskips 0 or -lruskips 100), the LRU latch accesses with -lruskips 100 are very low compared with the other latches. It is now far from being the biggest bottleneck in the system. So yes, you could increase -lruskips further, but at that point, it is a matter of diminishing returns. Also, there is a potential risk of setting it too high. Every time a block is promoted to the MRU end of the LRU chain (i.e., it is not skipped), it is “rescued” from reaching the LRU end and being out-paged. If a block is accessed relatively infrequently and there is a relatively small buffer pool, it could be skipped enough that it reaches the end of the chain and is out-paged. Then, on its next access, a physical I/O is required. So setting -lruskips too high could worsen performance.
The -lruskips param is intended to deal with that “thrashing” that can occur when you have code running in a tight loop and time is needlessly spent shuffling a relatively small collection of blocks between positions quite close to the MRU end of the chain. It does that well.
Note that in 12.1, the defaults for -lruskips and -lru2skips were changed from 0 to 100."
"It is (indeed) a question of diminishing returns.
-lruskips 1 = 1/2 # 50% of LRU housekeeping eliminated, twice the LRU request throughput available for the same CPU effort before waiting at the old level
-lruskips 2 = 1/3 # 66% of LRU housekeeping eliminated
-lruskips 4 = 1/4 # 75% of LRU housekeeping eliminated
…
-lruskips 10 = 1/10 # 90% of LRU housekeeping eliminated, 10X the LRU request throughput available for the same CPU effort before waiting at the old level — BHT latch waits are probably a problem before this actually happens
…
-lruskips 100 = 1/100 # 99% of LRU housekeeping eliminated, 100X the LRU request throughput available for the same CPU effort before waiting at the old level — BHT latch waits will certainly be problematic long before this actually happens
…
-lruskips 200 = 1/200 # 99.5% of LRU housekeeping eliminated
…
-lruskips 1000 = 1/1000 # 99.9% of LRU housekeeping eliminated
You would need charts that show LRU latch waits with and without the parameters in question (see the image above).
When we run into a customer that does NOT have -lruskips set and who has LRU latch waits, the impact of enabling LRUSKIPS is instantly obvious. It’s about as close to a silver bullet as anything since the introduction of -spin back in the day… It would be great to screen-capture that (we did, see the image above).
Setting it higher and higher basically has almost no impact. You _could_ show by setting it higher and higher and showing that LRU waits don’t get notably lower than “practically none.”
At the extreme, if you set -lruskips close to or larger than -B, then the “lru" aspect of the eviction algorithm* stops making any sense, and evictions become essentially random.
* The -lruskips parameter changes the algorithm from a strict "*least*" recently used” to “not very recently used.” Still, if you set it ridiculously large relative to the number of blocks, nothing looks like it has been recently used, so the algorithm becomes useless."